I’ve been messing around with making some dockerised Python applications run a bit faster. Imagine my surprise when I found out that the Docker-official Python images don’t have PGO enabled! Someone graciously provided some benchmarks saying that it was faster by a decent amount, and I’ve resolved to build our own Python base layer (maybe reusing RevSys’s Optimised Python image). But, I thought – is there anything more I can do? The machines that these dockerised applications are targeted for all use the same CPU generation, so I might be able to take advantage of some architecture-specific optimisations when compiling CPython.
First: What’s PGO?
CPython 3.6 (and 3.5.3) introduced a new compile-time configuration flag, --enable-optimizations. This flag enables Profile Guided Optimisation, a process where the code to be optimised is first compiled with profiling enabled, run on some representative code (in this case, the Python test suite), and then recompiled with the knowledge of how that profiled code ran to provide a more efficient binary.
This basically has no downside at runtime, only downsides at compile time. Firstly, you are doing the whole compile twice (first profiler-enabled, then optimised), as well as running the entirety of your representative code suite. On my computer the compile time (using make -j8) went from 1 minute to 24 minutes. This isn’t so bad if you’re compiling one Python to keep around for good, but when you’re compiling 38 variants on public CI, it can be unacceptable – which is why the Docker-official Python images don’t have it enabled.
OK, I can deal with an extra 20 minutes. What do I get?
Well, you get faster performance. But, first, I wanted to see if the second variable in the mix – architecture-specific optimisations – provided any extra benefits by itself.
Firstly, my computer specifications (not that some things matter :) ):
| OS | Arch Linux x86_64 |
| Kernel | 5.1.16-arch1-1-ARCH |
| GCC Version | 9.1.0 |
| Motherboard | Gigabyte AX370M-Gaming 3 |
| CPU | AMD Ryzen 5 2600 @ 3.4GHz |
| GPU | NVIDIA GeForce GTX 1660 Ti |
| Memory | 32GB @ 2666MHz, Dual-Channel |
The ‘m’ in ‘march’ stands for ‘MEGA’
x86-64, as a -march argument, represents the base level of all 64bit CPUs. This limits the compiler to the base 64-bit instructions (which include and superscede SSE and SSE2) and not much else. However, it will run on all x86-64 CPUs, all the way back to 2005’s Prescott 2M-based Pentium 4s. (note: 2003-2005 “AMD64” and “Intel 64” CPUs lacked some instructions that modern Windows requires in 64-bit mode. I’m not sure if GCC works around the missing/incorrect instructions. It’s likely newer compiler suites like Clang/LLVM simply do not.)
Since my CPU is a Ryzen, -march=native translates into -march=znver1. On Amazon’s latest t3 category of virtual instances, -march=native would turn into -march=skylake-avx512, as they run on Intel Xeon Platinum 8175M CPUs (which have AVX-512, unlike regular Skylake).
This is what these march options translate to in terms of GCC option flags:
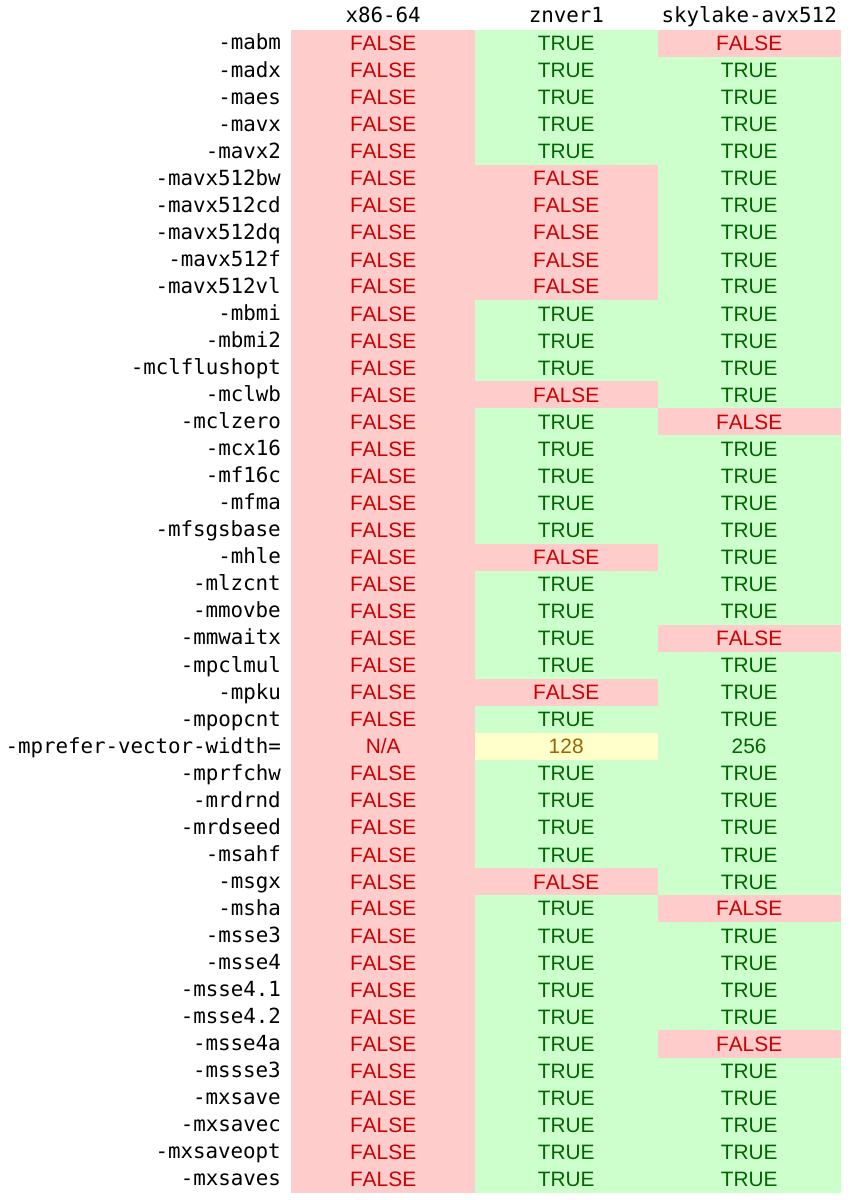
Of note is the enabling of SSE3, SSSE3, SSE4, SSE4.1, SSE4.2, SSE4a (on AMD), and AVX instructions (with 512-bit AVX on the Skylake chip). Of course, these instructions being enabled doesn’t mean they will be used – generally, specialised code is needed to take advantage of advanced processor features, with the compiler only able to do “obvious” optimisations to generic code (like CPython). SSE3 is specifically multimedia focused, but SSE4 was designed to be more generic (with SSE4.2 coming with a CRC32 instruction and string comparison functions).
Actually, it stands for ‘machine’. I just like the sound of ‘MEGA ARCH’
So, with all that out of the way, I went and compiled two versions of CPython 3.7.3 – one with CFLAGS set to -march=x86-64 -mtune=generic and one with CFLAGS set to -march=native. No optimisations were enabled here – I just wanted to see if the compiler optimisations gave me any benefits.
For my benchmarking, I used Python’s standard benchmark suite with its standard options.
(Naturally, take all benchmarks with a grain of salt. Due to random fluctuations of atomic rays, something might just be slow for no reason. I made sure the computer was idle when performing the benchmarks, and pyperformance utilises multiple runs to get more stable results. But: don’t be surprised if you get slightly different numbers!)
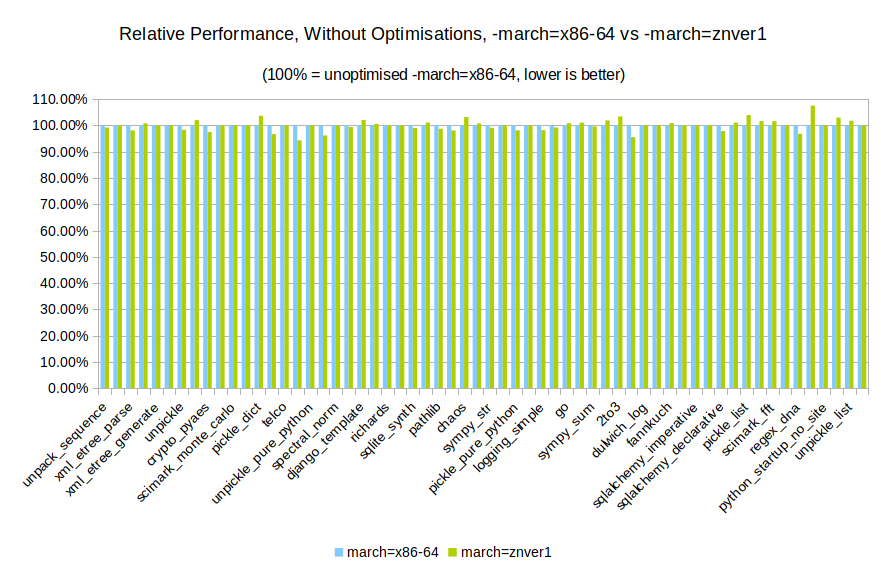
It seems that there’s not much difference between the two, there. Maybe it won’t make such a big difference?
RTX ON! Wait…
After that, I compiled a Python 3.7.3 with CFLAGS set to -march=x86-64 -mtune=generic and --enable-optimizations given in the configure step, and ran the tests again.
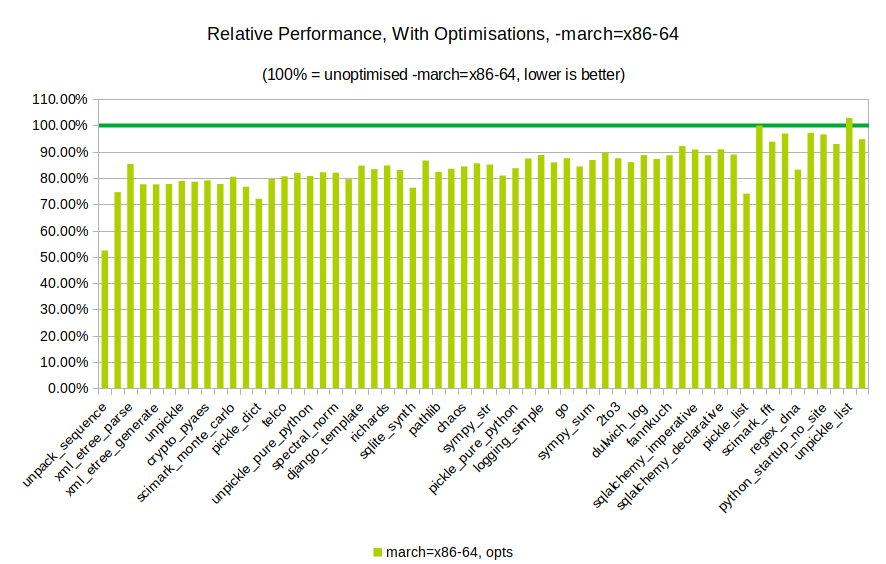
Woo hoo! As you can see, a 20% reduction in time taken can be achieved with CPython’s PGO compile-time run.
Considering there was little difference in the different -march options in an un-optimised build, what about with the optimisation on in a -march=native build?
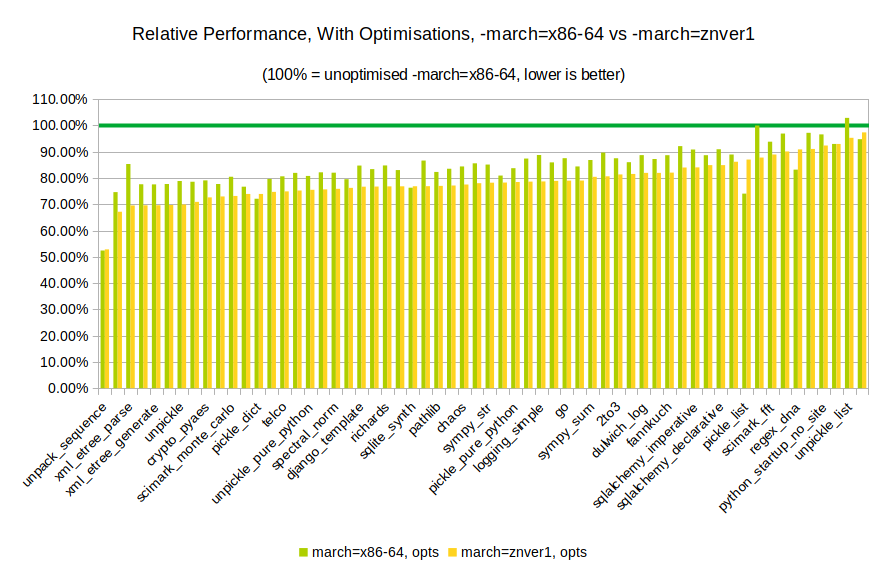
This is rather interesting! The architecture-specific optimisations do make a difference when profile guided optimisation is used.
Now, let’s compare the difference between the two directly, without worrying about the unoptimised builds:
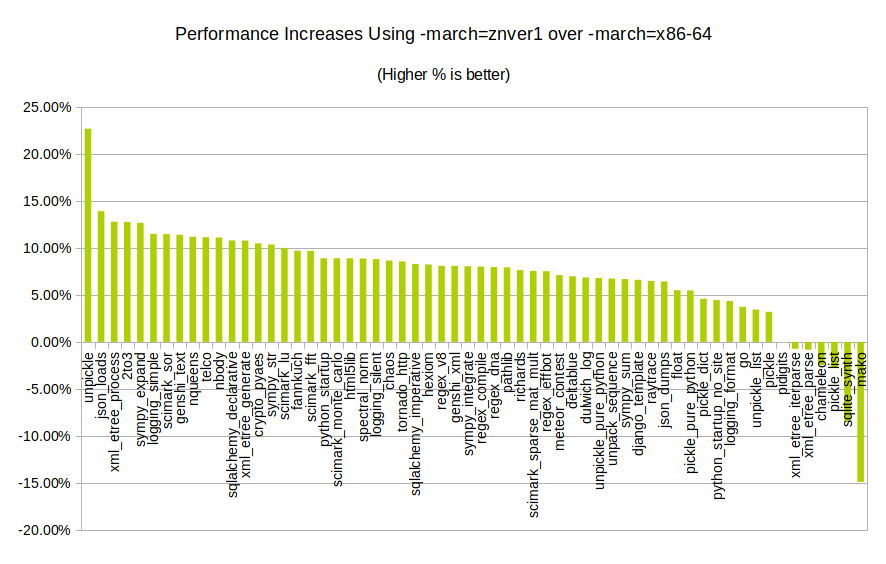
It appears that some benchmarks (like JSON loading and a smattering of scientific workloads) potentially get a 5 to 10% performance boost over the regular optimised builds with an architecture-optimised build of Python. Whether this is due to AVX, SSE3 or SSE4, I’m not sure. The drop in performance for mako is concerning, and is an example of how optimisations don’t always make things faster in the real world.
Try it out yourself!
pyperformance comes with its own test harnesses and comparison code, so you can compare how well potential optimisations perform on your specific hardware with it. Try it out!
Additionally, you can get my working out here, if you wish.
Conclusions
--enable-optimizations, if you can pay the compile cost, is absolutely worth it.
-march=native seems a lot more situational. For my Ryzen 5 2600, it appears to give a nice little boost in some things I might care about. I estimate the modern Xeons, with SSE3+4+etc, would give similar boosts, and I will certainly be measuring the difference on the hardware. On your setup, it might not bring you much. The only way to know is apply the tried and tested performance measuring method of trying it and measuring it!